Mitch Richling: Some Software
| Author: | Mitch Richling |
| Updated: | 2022-12-08 |
Table of Contents
- 1. Introduction
- 2. Render and display bits of LaTeX
- 3. Simple hexadecimal dump
- 4. Playing nice: X clipboard, Screen buffer, & the shell
- 5. A replacement for cat, zcat, bzcat, gzcat, lzcat, etc…
- 6. Analyze Byte Frequency And Characters
- 7. ASCII & Unicode tables (with UTF-8) in a terminal
- 8. Delete temporary files created by TeX & LaTeX
- 9. Mitch's Poor Man's File Server (MPMFS)
- 10. Working with Debian & Ubuntu packages
- 11. Mitch's Poor Man's Web Server (MPMWS)
- 12. Checksum Tools
- 13. Set theoretical file comparison and manipulation
- 14. Stable
uniqcommand
1. Introduction
Linked below you will find a few software tools I have written over the years. Most of them are UNIX centric. You can find a few more tools intended for UNIX system administrators here. You may also be interested in some of the code on may Programming Examples page as well.
2. Render and display bits of LaTeX
I frequently encounter bits of LaTeX code in e-mails and on the web (on social networks, in source code comments, and journal article abstracts). While most are simple enough to decode in my head, many are complex enough that a little software assistance is more than welcome. The script latexit.rb takes little bits of LaTeX code, renders a high quality preview, and pops up the result on the screen. It can do this from the command line (processing its arguments or standard input), and so may easily be integrated with other software. I have integrated it with my e-mail client, my editor, and into a generic GUI.
I use GNU Emacs as my editor. I wanted to be able to highlight a bit of LaTeX and hit a
button to see it rendered. The wonderful thing about Emacs is that it really is a fully programmable editor. Integrating latexit.rb with Emacs was easy. I
added the following to my .emacs:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; (defun MJR-latexit() "This function runs latex on the highlighted region, and displays the result with xpdf. Use the latexit.rb script in my home directory -- handy to have inside of Emacs..." (interactive) (let* ((reg-min (if (mark) (min (point) (mark)) (point-min))) (reg-max (if (mark) (max (point) (mark)) (point-max)))) (if (file-exists-p "~/bin/latexit.rb") (shell-command-on-region reg-min reg-max "~/bin/latexit.rb -") (message "MJR: MJR-latexit: ERROR: Could not find the latexit.rb command!"))))
I also integrated latexit.rb into an (ugly) little GUI, latexitGUI.rb that I pop up right beside my browser window when
browsing mathematical journals on the web. The GUI is written in Ruby version 1.9.1.
3. Simple hexadecimal dump
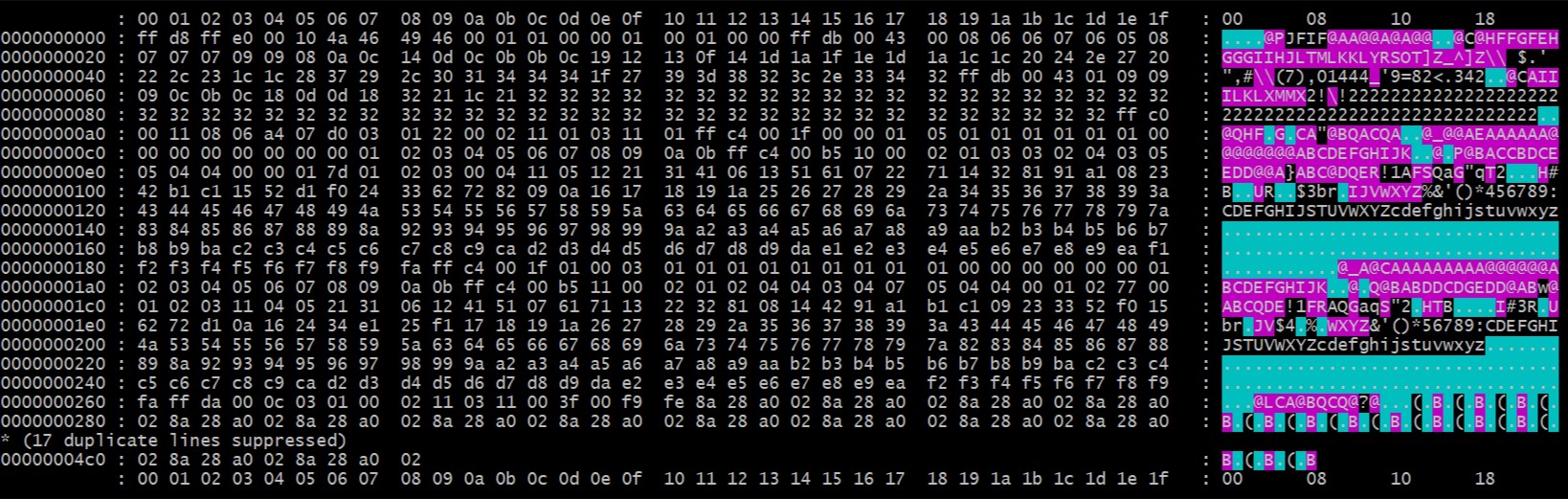
I sometimes find myself on a platform without od or hexdump, so I keep my own little hexDump.rb ruby script on my thumb
drive. It produces a "canonical" hex dump of whatever data you give it. The format is quite wide and uses terminal colors to denote non-printable characters
– I generally use quite large, color xterms.
4. Playing nice: X clipboard, Screen buffer, & the shell
The mjrclip.sh script allows one to copy data between Standard In/Out, the X11 clipboard, and a Screen buffer file. This
script is a huge productivity boost even on a standalone workstation, but becomes almost magical in networked UNIX/Linux environments. I run almost all my
interactive shells inside screen sessions. Those screen sessions might be connected to GNU Emacs, an X11 terminal (xterm,
rxvt, etc.), or to a dumb console session. The screen session is frequently running on a machine different from the one it is being displayed on. Most of
the time all of my screen sessions will share the same buffer file across all systems on the network (NFS or AFS mounted home directory and shared directories
between hypervisor and guests). This allows me to cut-n-paste between systems running different X11 sessions, or even between different machines that are not
running X11 at all!!! That's right: MAGIC! Research a problem on your laptop running X11, highlight the command line you need on your laptop, roll your
chair over to that broken server with the dumb Linux console, and simply paste that command into your shell session. It really is like magic.
5. A replacement for cat, zcat, bzcat, gzcat, lzcat, etc…
If you want to cat a file and don't want to worry about if it is compressed or not, then universalCat.sh may be just what
you are looking for. This little script is very useful for simplifying commands in tools that support reading piped output from shell code (things like
GNUplot and fread in R
It is also handy for simplifying scripts that may need to work with both compressed and uncompressed files. Lastly, it is a lifesaver when one of your
colleagues has compressed some files you want to work with, but not others – or has used different compression methods for different files. This is a super
simple script, but I find myself using it quite a bit. I link it to ucat in my personal bin directory.
6. Analyze Byte Frequency And Characters
The file command is great. It lets you know what kind of file you are working with – most of the time. That said, sometimes I need to know more about the
structure of a file from a statistical perspective. That is what byteAnalysis.rb is designed to do. It computes statistics
regrading the distribution of bytes (or characters) within a file as well as a few targeted checks for things like UNICODE and line endings.
7. ASCII & Unicode tables (with UTF-8) in a terminal
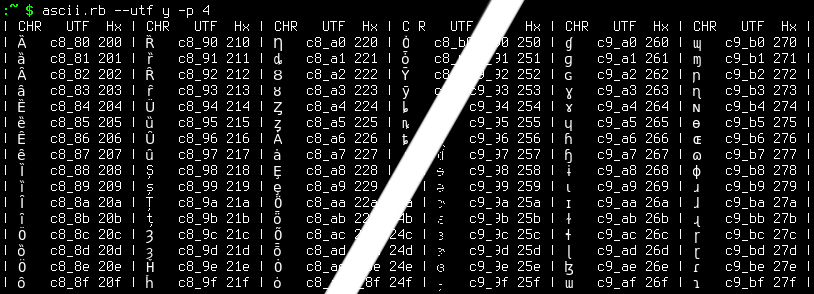
Sometimes all you need is a simple, nicely formatted ASCII table in your terminal (or GNU Emacs session) with character point
values in hexadecimal, octal, or decimal. If that is what you need, then ascii.rb may be just what you are looking for! If your
terminal supports Unicode then you can get Unicode tables too – in which case you can also have the bytes of the UTF-8 encoding printed in the table. Note
the display encoding can be selected, so if your terminal uses something other than Unicode, you can usually make it work.
8. Delete temporary files created by TeX & LaTeX
LaTeX and TeX create a great number of temporary files that can seriously clutter up your hard drive. This little script,
nuke_tex.sh, finds and deletes these temporary files in a relatively safe way – note that I did not say "complete safe",
I said "relatively safe". The algorithm used is to find .tex files, and then delete files in the same directory with the same base name and an extension
typically associated with temporary TeX files. The only exception is directories named 'auto' – they get deleted if any .tex file is fond in the same
directory – these auto directories get created by Emacs.
9. Mitch's Poor Man's File Server (MPMFS)
mpmfs.rb is a ruby script that implements a file-server (with a few extra bits) as a web service (a specialized HTTP server)
using Ruby. Some of the things it can do:
- Read/Write access to the current host's file-system.
- Pure Ruby file manipulation (touch, chmod, etc.)
- UNIX command/shell access
- File manipulation (touch, chmod, etc..)
- System information (top, df, who, etc..)
- RPC-like access via HTTP GET to access raw shell command output.
- A usable interactive shell access with command history.
- Supports SSL and HTTP based user/password authentication
- Functions through HTTP proxies and over SSH tunnels
- Works well with text browsers (Lynx & w3m)
- Isn't terribly ugly on GUI browsers (firefox, safari, IE)
- Decent support for Windows XP
Normally MPMFS is bound to the host's loop-back interface (localhost or 127.0.0.1) so that it may be accessed by any local processes. If the local host is shared with other users, then HTTP authentication should be used to prevent access. To access a MPMFS server from a remote host, an SSH tunnel is the usual solution. An alternate way of accessing an MPMFS remotely is to bind it to an externally visible interface. When used in this way, it is probably a good idea to turn on both SSL and HTTP authentication. For the ultimately paranoid, using SSL, HTTP authentication and an SSH tunnel in combination may be just the ticket.
10. Working with Debian & Ubuntu packages
I do a lot of development, and most of the time if I install a library I also what the associated documentation and/or development files for that library.
Debian puts this stuff in different packages, and sometimes I forget to install them all. To help me keep track of things, I have a little script that looks
at the current system and tries to find all of the related packages that I may have forgotten to install:
debFindRelatedPackages.rb
I find myself comparing package lists on different Debian and/or Ubuntu systems quite a lot – why is this tool working on machine A but broken on machine B,
did I get all my favorite stuff installed after an upgrade, do all the systems on my home network have the same packages, etc… For these, and related
tasks, I have a little helper script: debCmpPackages.rb.
11. Mitch's Poor Man's Web Server (MPMWS)
mpmws.rb is a little ruby program that implements a simple web server providing browsable directory index lists, HTML index
support (index.html), and CGI support. While not as sophisticated as web servers like Apache, this web server is more than adequate for testing things like
CGI scripts client side AJAX-style code.
12. Checksum Tools
Making sure files transferred across the Internet arrived unharmed or that backups really contain faithful copies of the data they protect are both problems
easily solved by checksums. dcsumNew.rb is a ruby script that can checksum entire
directory trees, and stores all sorts of filesystem metadata in an an SQLite DB. The scheme used is pretty flexible and provides a rich source for data
analysis. dcsumCmp.rb is a ruby script that can compare two checksum files – both
using the old text file format and the newer SQLite file format. These scripts and more may be found on github,
and the documentation may be found here.
13. Set theoretical file comparison and manipulation
I frequently want to do set theory things with the lines in a file. For example, I might have a set of files each containing a list of installed packages on a machine, and I want to know things: 1) what packages are installed on all systems (set intersection), 2) what is the list of all installed packages (set union), 3) what packages are only installed on machine A (set difference), 4) etc… These tools facilitate such computations (see the script documentation for more examples).
lineSetOp.rb is a ruby script that can do many different kinds of set theory computations.
Each "set" is defined by a file with the set elements being each line of the
file. lineMapDiff.rb is similar to
lineSetOp.rb but it operates on maps (ordered pairs) instead of sets, and only preforms a
kind of set difference. These scripts and more may be found on github,
14. Stable uniq command
The POSIX uniq command takes line oriented input, and drops any line that is equal to the previous line. When the input is sorted lines, then the output is
the a unique set of distinct input lines – that's where uniq gets its name. Sometimes I want the unique lines in a file, but I don't want to disturb the
order of the input data. For example, I might want to zap the duplicates in my shell history file, but I don't want to change the order because that will
make history searches awkward. That is to say, I want the first occurrence of every line, and any duplicates appearing later in the file removed.
uniq.rb is a ruby script that will do just that. This script and more may be found on
github,